


Yapay zekâ (AI), yeni ilaçların keşif sürecinin riskini azaltmayı vaat etmektedir. Szalay (2023) tarafından yayımlanan “AI in drug discovery”, Türkçe ifadeyle “İlaç Keşfinde Yapay Zekâ” adlı makalenin bu çevirisinde ilaç endüstrisinin ilaç keşfinin ilk aşamalarında riski azaltmak için nasıl yeni bir iş modeli benimsediği ortaya konulmaktadır. Yapay zekânın maliyet ve zaman tasarrufu yoluyla ilaç keşfini nasıl hızlandırabileceğine ve ilaç ve yazılım endüstrileri arasındaki boşluğu doldurmak için “açıklanabilir yapay zekânın” rolüne bakmaktadır. Son olarak, erken keşif akademiden ve büyük ilaç şirketlerinden daha küçük start-up’lara ve biyoteknoloji spin-off’larına kaydıkça, özel altyapı ihtiyacını inceliyor. Startup, aşırı belirsizlik koşulları altında yeni bir ürün veya hizmet yaratmak için tasarlanmış bireysel bir girişimdir (McGowan, 2022). Spin-off girişimler ise bir ana şirketin bir yan kuruluştaki veya iş bölümündeki hisseleri ana şirket hissedarlarına dağıtmasıyla oluşturulan yeni ve ayrı bir şirkettir. Bir tür elden çıkarma işlemidir. Bir ana şirket, bağımsız bir varlık olarak ana şirketin bir parçası olduğundan daha değerli olacağı beklentisiyle bir yan şirket kurar. Spinoff aynı zamanda spinout veya starburst olarak da bilinir. Spinoff, bir ana şirketin mevcut bir işletme veya bölümdeki hisseleri ana şirket hissedarlarına ihraç etmesiyle oluşturulan bağımsız bir şirkettir. Bir spinoff kendi yönetim yapısına ve yeni bir isme sahiptir. Ancak ana şirketten finansal ve teknolojik destek almaya devam edebilir. Spinoff’lar hissedarlar için iyi yatırımlar olma eğilimindedir (Fontinelle, 2023).
Yapay zekâ ilaç keşfini değiştirecektir. Yeni bir ilacı piyasaya sürmenin temel zorluğu, ilacın etkinliğinin hastalar üzerinde test edilerek ortaya çıkarılmasından önce çok fazla zaman ve para gerektirmesidir. YZ, ilaç keşfinde giderek daha fazla adıma entegre edildikçe, ana etkisi en iyi başarı şansına sahip deneylerin seçilmesi ve böylece keşif sürecinin riskinin azaltılmasıdır. Verimlilikteki mütevazı bir artış bile bir ilaç piyasaya sürülene kadar büyük tasarruflar sağlayabilmektedir.

YZ sistemlerinin ilaç keşfini geliştirme yeteneği söz konusu adıma bağlıdır. Açıklanabilir YZ, YZ’nin henüz yaygın olarak kullanılmadığı ilaç keşfi adımları üzerinde büyük bir etkiye sahip olabilir. Bununla birlikte, tasarım gereği açıklanabilir olan YZ yaklaşımları henüz yeterince iyi değildir. Uygulama alanları ne olursa olsun, YZ’nin “kara kutu” formları için açıklanabilirlikte teknik ilerlemelere hala ihtiyaç vardır.
İlaç sektöründe yapay zekânın benimsenmesi şaşırtıcı derecede hızlı olmuştur. YZ çözümleri, hızlı ancak güvenilmez tahminler sağlama konusunda bir üne sahiptir. Durum böyle olduğu ölçüde ilaç endüstrisinin güvenlik odağı ile bir gerilim söz konusudur. Gerçekten de YZ’yi doğrudan hasta başına getirmek pek işe yaramamıştır (Herper, 2017). YZ, Ar-Ge sürecinin sınırları içinde kaldığı sürece, deneyler, hastalar dahil olmadan önce tahminlerini doğrulayabilir.
Hasta güvenliğini sağlamak için titiz deneylere her zaman ihtiyaç duyulacaktır. Bununla birlikte, YZ’nin potansiyel etkisi klinik deneylere olan ihtiyacı ortadan kaldırmak değildir. Aksine, yeni ilaçların sonunda klinik deneylere ulaştıklarında daha az başarısız oldukları bir durum ortaya koyabilir.
1990’ların sonlarından itibaren, ilaç endüstrisindeki verimlilikte büyük bir düşüş yaşanmıştır. Bu düşüş 2010’larda da devam etmiştir.
Neyse ki yeni teknolojiler – özellikle CRISPR ve ilaç güvenliğinin daha iyi tahmin edilmesi – ilaç keşfinde bir çöküşü önlemeye yardımcı olmaktadır. Yeni ilaç onaylarının maliyeti son on yılın sonunda büyük ölçüde istikrar kazanmıştır (Şekil 1). Ancak yeni ilaçların piyasaya sürülmesi riskli olmaya devam etmektedir; klinik deneyleri tamamlanan ilaçlar için bile başarısızlık oranları %60’ın çok üzerindedir (Wong, 2019).
Büyük ilaç şirketleri, ilaç keşfinin ilk aşamalarındaki riski azaltmak için yeni bir iş modeli bulmuştur: küçük biyoteknoloji şirketlerinden ilginç bileşiklerin lisansını almak. İlaç şirketleri, keşfin ilk aşamalarında karşılaşılan riskleri küçük şirketlerin üstlenmesi karşılığında bu bileşikler için bir prim ödemiştir. Büyük şirketler en iyi yaptıkları işi yapmıştır: sermaye yoğun klinik deneyler ve ticarileştirme. Bu eğilim son on yılda hız kazanmıştır.
Büyük şirketlerin karmaşık iş süreçleri vardır ve değişim hem bireyler hem de kuruluşlar için zordur. Sonuç olarak, YZ teknolojilerinin kullanımında bir patlamanın yaşandığı yer, çevik küçük biyoteknoloji şirketleri olmuştur. YZ çözümleri, ilaç keşfine halihazırda önemli bir değer katabilir. Bununla birlikte, birçok uygulama henüz büyük ilaç şirketlerinin karmaşık, optimize edilmiş (ve dolayısıyla zorunlu olarak daha katı) süreçlerinde benimsenebilecekleri bir olgunluk seviyesine ulaşmamıştır.
İlaç keşfinde yapay zekânın vaatleri
- Daha yaratıcı ve daha hızlı deneyler
YZ’den ilaç keşfi üzerinde ne kadar etki beklenmelidir? Deneylerin çoğu laboratuvarlarda, hücre kültürlerini ölçerek veya özel deneyler (bilgisayarda deney yapmanın “kuru-lab” çalışmasının aksine genellikle ıslak-lab olarak adlandırılır) ile ilaca bağlanarak yapılır. Yüksek verimli ıslak laboratuvar deneyleri bile nispeten yavaş ve pahalıdır. Bu nedenle, en son teknolojiye dayalı olarak yürütülmesi mantıklı olan deneyleri seçmek için her zaman insan uzmanlığı gereklidir. Yapay zekâ tahminlerini çalıştırmak için böyle bir ön seçime gerek olmadığından, makine öğrenimi sistemleri aklı başında hiçbir insan ilaç avcısının işe yaramasını beklemeyeceği yeni fikirler bulmaya yardımcı olabilir. Bu tür yenilik üretiminin değerini ölçmek zor olsa da, YZ tarafından oluşturulan deney listesi, tasarruf elde etmeye yardımcı olmak için laboratuvarda çalıştırılmak üzere kullanılabilir. Bu yaklaşım, yapay zekâ sisteminin rehberliği olmayan bir yaklaşıma göre daha kısa ve muhtemelen daha başarılı olacaktır.
- Her aşamadaki başarısızlıklarla ilişkili maliyet ve zamanın azaltılması
Yenilik bulmanın yanı sıra, yapay zekâdan beklenen diğer önemli etki, ilaç keşfinin her aşamasında başarısızlıklarla ilişkili maliyet ve sürenin azalmasıdır. Bu azalmalar ölçülebilir. Keşif sürecinin her adımında başarısızlık oranını %20 azaltmak (örneğin %30’dan %24’e), herhangi bir projenin toplam maliyetini yarıya indirmek anlamına gelecektir.
Veriler ayrıca genellikle başarısızlık oranını azaltmanın en iyi seçenek olduğunu göstermektedir. Bununla birlikte, ilaç keşfinin ilk aşamalarında, daha az deney yaparak maliyet tasarrufu sağlamak, başarısızlık oranlarını azaltmaktan daha önemlidir. Şekil 2, ilaç keşfinin tüm adımlarında son teknoloji YZ rehberliğinden elde edilen tahmini maliyet tasarruflarını göstermektedir. YZ araç geliştiricilerinin en fazla etkiyi sağlayan uygulamalara odaklandığı varsayılmaktadır. Bu tasarruflar, yeni ilaç başına bir milyar ABD dolarının biraz üzerinde olacaktır (Bender ve Cortés-Ciriano, 2021).
- İlaç geliştirmek için gereken minimum hasta popülasyonunun daha küçük olması
Ar-Ge maliyetinin azaltılması, hastalar için genellikle çok pahalı olan ve/veya kamu bütçelerine büyük yük getiren yeni ilaçların fiyatını düşürebilir. Ayrıca, daha küçük hasta popülasyonları için ilaç geliştirmeye başlamak mümkün hale gelebilir ve böylece nadir hastalıkların yanı sıra kişiselleştirilmiş yaklaşımlara ihtiyaç duyan yaygın hastalıklar için de ilaç keşfi mümkün olabilir. Örneğin DeSantis, Kramer ve Jemal (2017) tüm kanserlerin %20’sinin nadir görüldüğünü ve dolayısıyla en yaygın kanserleri hedefleyen ilaçların kapsamına girmediğini vurgulamıştır. Zaman içinde YZ tabanlı ilaç keşfinin tartışmasız en büyük faydası yeni bir ilaç geliştirmek için gereken minimum hasta popülasyonunun küçültülmesi olacaktır.
Şekil 1. Yeni ilaç onayı başına ortalama reel maliyet, 1984-2019 (2019 yılı milyar ABD doları)
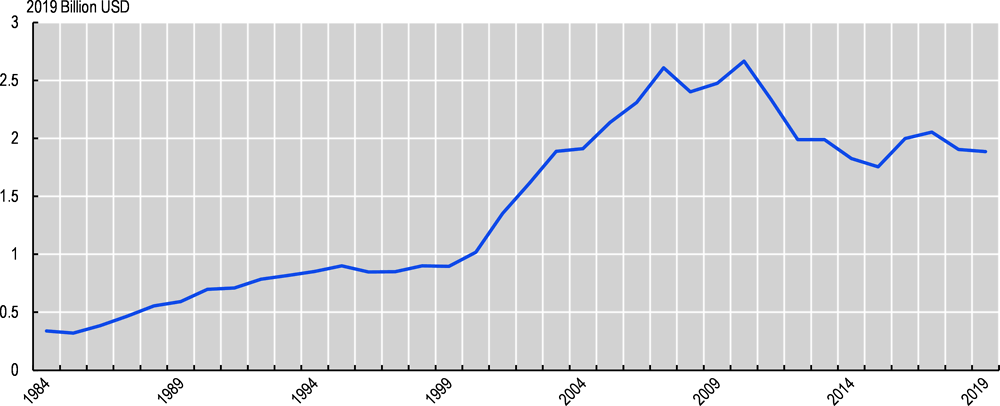
Not: Amerika İlaç Araştırma Üreticileri üye firmalarının Gıda ve İlaç İdaresi (FDA) yeni moleküler varlık onayları başına yaptıkları yıllık Ar-Ge harcamalarından hesaplanmıştır (beş yıllık hareketli ortalama).
Kaynak: Kongre Bütçe Ofisi (2021): Kongre Bütçe Ofisi (2021)
Yapay zekâ günümüzde ilaç keşfinin farklı aşamalarında nasıl kullanılıyor?
- Proteinlerin nasıl katlandığını anlamak
Son zamanlarda manşetlere çıkan bir yapay zekâ uygulaması ile potansiyel ilaç hedeflerinin yapısı ve dinamikleri daha iyi anlaşılabilmektedir. Deepmind’ın Alphafold2’si, araştırmacıların proteinlerin 3D yapısını anlamalarına yardımcı olan bir yapay zekâ sistemidir. Bu, biyolojide son derece önemli bir sorundur çünkü proteinlerin dünyasında işlevi biçim belirler. Gerçekten de çoğu ilaç keşif süreci, belirli bir hastalık için hedeflenecek doğru proteini bulmakla başlar. İnsan proteomundaki (insanları oluşturan proteinlerin tamamı) proteinlerin küçük bir alt kümesinin şekli hakkında iyi deneysel veriler mevcuttur. Ancak bilim, çoğu insan proteininin çalışan, katlanmış formunun neye benzediği hakkında hiçbir fikre sahip değildir.
Şekil 2. Tipik bir ilaç keşif projesi için, ilaç geliştirmenin her aşamasında başarısızlık oranının veya maliyetin %20 azaltılmasıyla (hangisi daha etkiliyse) elde edilen net tasarruf (Milyon ABD Doları)
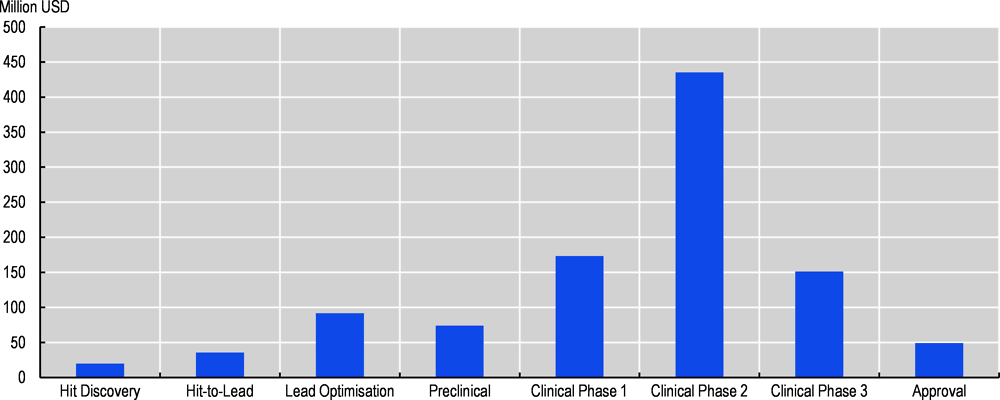
Kaynak: Bender ve Cortés-Ciriano (2021)
Deneysel veriler üzerinde kapsamlı bir eğitim ve akıllı bir yapay zeka mimarisi ile Alphafold2 , CASP14 (CASP14, n.d.) yarışmasında daha önce yayınlanmamış bir dizi protein yapısı için deneysel sonuçlara yaklaşan tahminler ortaya koymuştur (Jumper et al., 2021). Bu, daha önce bilinmeyen proteinlerin yapısını güvenle tahmin etmenin yolunu açmaktadır.
Sistemin yayınlanmasından sadece birkaç ay sonra, tüm insan proteinleri için Alphafold tarafından tahmin edilen protein yapılarını içeren veritabanları bilim insanlarının kullanımına sunulmuştur (Varadi vd., 2022). Bu ilerleme, ilaç endüstrisindeki araştırmacıların, hedef proteinin gerçekte neye benzediğini iyi bir şekilde anlamalarını mümkün kımaktadır. Bu sayede ilgilenilen bir proteini hedefleyecek molekülleri bulmalarına büyük ölçüde yardımcı olmaktadır.
- Doğru proteini hedefleme (“hedef keşfi”)
Bir sonraki adım, belirli bir hastalık için hangi proteinin hedef alınacağını bulmaktır. Laboratuvarda iyi ilaç hedefleri bulmanın tek bir en iyi yolu yoktur. Farklı deneysel testlerin farklı güçlü ve zayıf yönleri vardır. Bu durum ilaç keşfindeki yapay zekâ yöntemleri için de geçerlidir. Farklı makine öğrenimi sistemleri – eğitildikleri verilere bağlı olarak – farklı analitik sorunları ele almada üstünlük sağlayacaktır. Bu nedenle, hedef keşfi üzerinde çalışan YZ şirketleri çoğalmakta ve her biri kendi keşif platformunu geliştirmektedir. Bu şirketler, hücre mikroskobu, elektronik tıbbi kayıtlar, genetik veri tabanları ve bilimsel literatürden elde edilen çeşitli verileri kullanarak kendi ilaç hedefi boru hatlarını oluşturmaktadır. Bu yöntemlerden bazıları ilaç keşfine girebilecek olsa da, yapay zekâ tarafından keşfedilen bir hedefe dayanan hiçbir ilaç henüz ABD Gıda ve İlaç Dairesi (FDA)’nden onay almamıştır. Bu tür ilk ilaçlar insan klinik deneylerine daha yeni girmiştir (Jayatunga, 2022). Bu durum, hedef keşfini, ilaç keşfinde YZ’nin heyecan verici, hızlı ilerleyen ancak henüz gelişmekte olan bir alanı haline getirmektedir.
- Doğru molekülü bulma (“isabet tespiti”)
Belirlenmiş bir protein hedefine sahip olunduğunda, tüm gözler ilgilenilen proteini inhibe edecek doğru molekülü bulunmasına çevrilmektedir. Yerleşik ıslak laboratuvar yöntemleri sadece birkaç gün içinde yüz binlerce ve milyonlarca küçük molekülü tarayabilse de, iyi isabetler (belirli bir protein hedefine seçici olarak bağlanan moleküller) sağlamak hala zorlu bir görevdir. Bunun nedeni, ilaç benzeri kimyasalların sayısının 1060 civarında, yani Dünya’daki atom sayısının bir milyon katı kadar olabilmesidir (Bohacek, McMartin ve Guida, 1996).
Gerçekten de iyi isabetler elde edebilmek ilaç keşfinde makine öğrenimi için ilk sınırlardan biriydi. Sanal tarama yöntemleri, ilgilenilen belirli bir hedefe bağlanabilecek moleküllerin hesaplamalı keşfini içermektedir. Örneğin “moleküler yerleştirme”, aday molekül ve hedef proteinin eşleşen yüzeylerini bulmaya çalışmaktadır.
Sanal tarama, ıslak laboratuvar taramasıyla mümkün olandan çok daha geniş bir alanı araştırabilir. Bu rakamlar, ticari olarak mevcut sanal tarama platformlarında 109 molekülden, tescilli ilaç kütüphanelerinde 1015 veya daha fazlasına kadar değişmektedir. Bu da ıslak laboratuvar taramasındaki 106 moleküle kıyasla 4 ila 9 mertebe büyüklük farkını temsil etmektedir (Hoffmann ve Marcus, 2019).
Sanal tarama araçları son yirmi yılda giderek daha sofistike hale gelmiştir (Goodsell vd., 2021) ve derin öğrenme yöntemleri de yakın zamanda bu alana katılmıştır (Wallach, Dzamba ve Heifets, 2015). Sanal tarama, YZ’nin ilaç keşfine yardımcı olduğu en köklü alt alan olsa da, bu alan hala ilaç benzeri kimyasal alanın çoğunu kullanabilmekten uzaktır. Genel olarak, YZ teknikleri, halihazırda ölçülmüş yapı taşlarının yeni kombinasyonlarının nasıl davranacağını tahmin etmede iyi çalışmaktadır. Ancak, yeni yapı taşlarının davranışını (bu durumda, yeni kimyasal yapıların davranışını) tahmin edememektedir.
- Daha rafine bir molekül üretme (“kurşun optimizasyonu”)
Kurşun optimizasyonu, klinik öncesi bir adayın belirlenmesiyle sonuçlanan kritik bir süreçtir. En umut verici hit serileri, hit-to-lead çalışmalarıyla belirlendikten sonra, ilaç keşfinin kurşun optimizasyonu aşamasına geçer. Bu aşamanın amacı, hem in vitro hem de in vivo deneylerden oluşan özel bir tarama hunisi aracılığıyla öncü serinin hem biyolojik aktivitesini hem de özelliklerini paralel olarak kapsamlı bir şekilde optimize etmektir. Tarama deneyleri ayrıca formüle edilecek ve dozlanacak en iyi bileşiği belirlemek için fizyokimyasal özellikleri değerlendirmek üzere tasarlanmıştır. Bileşikleri ve seriyi ideal aday profiline doğru hızlı bir şekilde değerlendirmek ve ilerletmek için titiz ve kritik veriler kesin ve zamanında üretilmelidir. Klinik öncesi adayların kalitesi ne kadar yüksek olursa, klinik geliştirmeye başarılı bir şekilde ilerleme olasılığı da o kadar yüksek olur (IRBM, 2023).
İlaç keşfinde, ilk umut verici moleküller bulunduktan sonra uzun bir yinelemeli kimya süreci izlenir. Bu süreç, daha iyi seçicilik, emilim ve dağılım özelliklerine sahip bir molekül olan daha rafine bir molekül (öncü olarak adlandırılır) üretmeyi amaçlar. Bu, sonunda in vivo olarak uygulanabilecek bir moleküle ulaşmak için yapılır. Yapay zeka, öncü optimizasyon sürecine de yardımcı olabilir. Ancak niceliksel olarak farklı bir sonraki aşama, bilim insanlarının hayvanlarda deneyler planlamaya başlamasıdır. İlk iki temel araştırma görevi, bileşiğin toksik olmadığından ve etkili olduğundan (hastalık durumunu iyileştirdiğinden) emin olmaktır.
İlaçların toksisite ve metabolik özelliklerinin değerlendirilmesi de hesaplamalı ilaç keşfinin temel dayanaklarından biri olmuştur. Son yıllarda, büyük ölçekli kamusal veri oluşturma çabaları (Kleinstreuer vd., 2014) ve yapay zekadaki genel ilerleme sayesinde modeller büyük ölçüde gelişmiştir. Hala sürprizler olsa da çoğu ilaç şirketi bazı metabolizma ve toksisite modelleme çözümlerini ana boru hatlarına entegre etmiş durumdadır.
İlaç tasarımı yoluyla biyobelirteçlerin tanımlanması (“klinik öncesi ve klinik aşamalar”)
Son adım ve ne yazık ki en zor olanı, molekülü hayvanlara ve daha sonra insanlara uygulamadan önce in vivo etkinliğini tahmin etmektir. Amaç, etkinliğin “biyobelirteçlerini” kullanarak hangi hastaların bir ilaca yeterince iyi yanıt vereceğini makul bir doğruluk derecesiyle ortaya koymaktır. Geleneksel biyobelirteçler kan testlerinden elde edilen ölçümler veya biyopsiden elde edilen mikroskobik bulgulardır. Ancak moleküler genetik testler daha sık kullanılmakta ve tıbbın giderek nasıl kişiselleştirildiğini göstermektedir. Bununla birlikte iyi biyobelirteçleri bulmak zordur.
Deneyimli bir ilaç avcısı, biyobelirteçler klinikte başarı için çok önemli olsa bile, yapay zeka desteğiyle bile bir ilaç için iyi bir biyobelirteç elde etmenin zor olduğunu söyleyecektir (Wong, 2019). Ne yazık ki, güvenilir biyobelirteçler bulmak çoğu YZ yöntemine uygun bir sorun değildir. Her hasta biyokimyası ile benzersizdir. Ayrıca, her hastaya yalnızca bir kez doz verilebilir. Kliniğe geri döndüklerinde, ilaç işe yaramış olsun ya da olmasın, tümör kompozisyonları muhtemelen değişmiştir. Bu da onları – eğitim amacıyla – farklı bir hasta haline getirir. Her iki husus da söz konusu ilaç için önceden hasta verilerine sahip olmadan güçlü biyobelirteçler bulmak üzere bir yapay zekâ sistemini eğitecek verilerin üretilmesini son derece zorlaştırmaktadır.
İlaç keşif ekiplerinin iyi biyobelirteçler bulma sorununu aşmasının bir yolu da ilacın yeniden tasarlanmasıdır. Bu, bir ilacın (ya onaylanmış bir ilaç ya da başarısız olmuş ancak güvenli olduğu gösterilmiş bir ilaç) alınmasını ve yapay zekâyı eğitmek için deneme verilerinin kullanılmasını içerir. Amaç, orijinal araştırma ekibinin gözden kaçırdığı veya öncelik vermediği yeni bir biyobelirteç tanımlamaktır. Ancak uygulamada, YZ tabanlı yeniden kullanım yaklaşımları çok başarılı olamamıştır. YZ’nin burada ne kadar katkıda bulunabileceği henüz belli değildir.
Açıklanabilir yapay zekâ, ilaç ve yazılım sektörleri arasında köprü kurmanın anahtarıdır.
- İlaç ve yazılım arasındaki uçurumun kapatılması
İlaç keşfine yeni YZ yöntemleri getirmenin zorluklarından biri derin bir kültürel bölünmenin yaşanmasıdır. YZ, “hızlı hareket et ve bir şeyleri kır” uygulamasının yapılabilir olduğu ve çoğunlukla iyi çalıştığı yazılım dünyasından gelmektedir. Öte yandan, yukarıdaki tartışmadan da anlaşılacağı üzere, güvenlik, ilaç keşfi kültürüne derinlemesine gömülüdür. Herhangi bir yeni ilacı piyasaya sürmek zaten son derece risklidir. Sonuç olarak, şirketlerin etkinliklerini kanıtlamak için yıllar ve yüz milyonlarca ABD doları harcaması gerektiğinde, yeni, kanıtlanmamış ilaç fikirleri anlaşılır bir şekilde nispeten daha az ilgi görmektedir.
“Açıklanabilir YZ” ye doğru ilerlemek, yazılım geliştirme dinamikleri ile ilaç endüstrisinin güvenlik ihtiyaçları arasındaki boşluğu doldurmanın bir yoludur. Açıklanabilir YZ, en iyi performans gösteren YZ sistemlerinin (sinir ağları gibi) genellikle açıklanabilir olmayan sonuçlar verdiğinin fark edilmesine yanıt olarak ortaya atılan bir kavramdır.
Açıklanabilir YZ’yi anlamaya yardımcı olmak için görsel tanıma yararlı bir benzetmedir. Görsel tanıma göründüğünden çok daha karmaşık, opak ve daha az bilinçlidir. Örneğin insanlar, bir kedinin içsel, anlık görsel tanınmasını tam olarak neyin tetiklediğini tanımlayamazlar. Sivri kulaklar, belirgin bıyıklar vb. gördüklerini düşünebilirler. Ancak bu kriterleri karşılayan başka hayvanlar da kolaylıkla bulunabilir. Açıklanamayan bir yapay zekâ sistemi (yapay sinir ağı gibi) tam olarak bu şekilde çalışır.
Karar ağaçları gibi diğer makine öğrenimi mimarilerinde karar süreci ve öğrenilen kurallar, eğitimsiz bir insan gözlemci için bile açıkça anlaşılabilirdir. Ne yazık ki, bu yorumlanabilir mimarilerin daha kötü tahmin performansı sunduğuna inanılmaktadır (Gunning ve Aha, 2019). Açıklanabilir YZ sistemleri, teorik olarak, açıklanamayan kara kutu sistemlerden daha kötü olmak zorunda değildir. Bununla birlikte, önde gelen modeller – derin öğrenme sistemleri – açıklanabilir değildir. Bu nedenle, herhangi bir problem için açıklanabilir bir YZ mimarisi seçmek kolay değildir.
- İlaç keşfinde açıklanabilirlik
İki argüman ilaç keşfinde açıklanabilirliğin önemini vurgulamaktadır.
Birincisi, ilaç keşfindeki bilim insanları halihazırda Lipinski’nin Beş Kuralı (iyi biyoyararlanıma sahip aday bir ilaç molekülünün nasıl görünmesi gerektiğine dair dört kuraldan oluşan basit bir set) gibi istatistiksel temel kuralları kullanmaktadır. Topluluk bu kuralların %100 doğru olmadığını kabul etmektedir. Ancak her bir kural bilimsel olarak anlamlıdır (örneğin, molekül çok büyük veya çok yüklü olmamalıdır).
İkinci olarak, bir ilacın keşfi, molekül ruhsatlandırma onayı alana kadar tamamlanmış sayılmaz. Aday molekülün istenmeyen yan etkileri veya istenmeyen metabolik özellikleri sıklıkla ortaya çıkar ve molekül yapısının veya hedef hasta popülasyonunun sürekli olarak değiştirilmesini gerektirir. Keşif ekibi, molekülün neden bu şekilde çalıştığını, nereye bağlandığını ve ilacın inhibe etmesi gereken biyolojik mekanizmayı iyi anlamadığı sürece bu mümkün değildir.
Ek harici yorumlama algoritmaları kullanarak kara kutu AI modellerinden “neden” in bir kısmını elde etmek mümkündür. Bununla birlikte, örneğin belirtilen hedeflerin basit bir sıralı listesi (örneğin 1. kolon karsinomu, 2. küçük hücreli olmayan akciğer kanseri) ilaç keşfi için yeterince iyi değildir. YZ ekibinin, sonuçlarının sorunsuz bir şekilde benimsenmesini sağlamak için her zaman şu veya bu şekilde bir açıklama sunması gerekir.
Açıklanabilirlik, verilerdeki “azınlık yanlılığının” tespit edilmesini sağladığı için de önemlidir. Yayınlanan veri tabanlarındaki genomik verilerin çoğu Kafkasyalılardan geldiği için öğrenme algoritmaları genellikle diğer bazı etnik gruplara özgü hastalık modellerini seçmekte zorlanır. Örneğin, Afroamerikalıların bazı ilaçları metabolize etme biçimlerinde küçük ama önemli farklılıklar vardır ve bu da farklı bir dozaj programı gerektirir.
Acil bir ihtiyacın farkında olan FDA, tıpta yapay zekâ için iyi bir düzenleyici çerçeve geliştirmek üzere halihazırda çalışmaktadır (FDA, 2021). Eylem planında özellikle a) kullanıcılar için şeffaflık, b) verilerdeki azınlık önyargılarının tanınması ve en aza indirilmesi, ve c) “iyi makine öğrenimi uygulaması” olarak kurallarının getirilmesi yer almaktadır. Tasarım gereği yorumlanabilir bir YZ’nin seçilmesi, büyük olasılıkla kara kutu bir model kullanılmasına kıyasla daha kısa bir uyum süresiyle sonuçlanacaktır.
- Modern yapay zekânın özel bir altyapıya ihtiyacı var.
Daha önce de belirtildiği gibi, erken keşifler akademiden ve büyük ilaç şirketlerinden daha küçük start-up’lara ve biyoteknoloji spin-off’larına kayma göstermektedir. Bu değişimin arkasındaki nedenlerden biri, modern yapay zekânın altyapı ihtiyaçları olabilir. Alphafold2 ve GPT-3 gibi çokça duyurulan çığır açan modeller milyarlarca parametre içermekte ve yüzlerce özel işlemci üzerinde haftalarca eğitilmektedir (Jumper, 2021). Bu tür devasa YZ sistemlerinde, her eğitim çalışması on binlerce ABD dolarına mal olmakta ve modelleri geliştirmeye devam etmek için sürekli olarak eğitim oturumları düzenlemek gerekmektedir. Bu da küçük akademik gruplara büyük bir mali yük getirmektedir.
Büyük modern YZ kurulumları için bir başka zorluk da tüm veri parçalarını ve kodu bu kadar büyük ölçeklerde bir araya getirmektir. YZ şirketleri, gerekli iskeleyi (veri işleme boru hatları, bilgi işlem kaynaklarının düzenlenmesi, veritabanı bölümleme vb.) inşa eden özel bir mühendis ekibine sahiptir. Bu şekilde her bir kod ve veri parçası, YZ’yi eğiten düzinelerce makinenin tümünde doğru zamanda doğru yerde bulunur. YZ, bir işletmenin ana odak noktasıysa toplanması mantıklı olan uzmanlık ve insan kaynaklarını gerektirir. Aksi takdirde, bu daha önce biyoloji yoğun çalışan firmalarda büyük bir paradigma değişikliği olacaktır.
Bu zorlukların üstesinden gelmek için akademik grupların, örneğin Amerika Birleşik Devletleri’ndeki Ulusal Yapay Zekâ Araştırma Kaynakları Görev Gücü (NAIRR Task Force, 2022) gibi daha güçlü bir yapay zekâ omurgasına ihtiyacı olacaktır. Avrupa Açık Bilim Bulutu veya ELIXIR gibi benzer konsorsiyumlar, bu alanda işbirliğini ilerletmek için yakın zamanda Avrupa Birliği’nde kurulmuştur. Ancak bunlar, akademide YZ’nin ölçeklendirilmesi sorununu çözmekten ziyade çoğunlukla veri ve araç paylaşımına odaklanmaktadır.
Sonuç
İlaç keşfinde yapay zekâ yeni bir olgu değildir. Makine öğrenimi, onlarca yıldır küçük molekül hedefleri oluşturmanın ayrılmaz bir parçası olmuştur. YZ’deki son ve devam eden gelişmeler, maliyetleri düşürmek ve verimliliği artırmak için ilaç keşif sürecinin diğer bölümlerine girmesine olanak tanımıştır. Son teknoloji ilaç keşfi, iş akışlarının temelini oluşturan moleküler yerleştirme ve toksisite tahmininin yanı sıra küçük biyoteknoloji şirketleri yapay zekâyı kullanmanın birçok yeni yolunu denemektedir. Bu da büyük ilaç firmalarının iş modelindeki değişimi hızlandırmaktadır. Bu firmalar, tüm araştırmaları şirket içinde yapmak yerine, dışarıdan denemeye hazır bileşikler satın almaktadır. Gerekli adımlardan bazıları hala çözülmemiş olsa da, tüm ilaç keşif hattında yapay zekânın başarılı bir şekilde benimsenmesi, ilaç geliştirme maliyetlerini önemli ölçüde azaltabilir. Bu sayede endüstri, SMA ve bazı kanser türleri gibi nadir hastalıkların yaşandığı çok küçük hasta popülasyonları için de ilaç üretebilecektir.
Faydalı olması ve farkındalık oluşturması dileğiyle.
Bilimle ve teknolojiyle kalınız.
Tevfik Bulut
https://tevfikbulut.net/
Yararlanılan Kaynaklar
- Bender, A and I. Cortés-Ciriano (2021), “Artificial intelligence in drug discovery: What is realistic, what are illusions? Part 1: Ways to make an impact, and why we are not there yet”, Drug Discovery Today, Vol. 26/2, pp. 511-524, https://doi.org/10.1016/j.drudis.2020.11.037.
- Bohacek, R.S., C. McMartin C and W.C. Guida (1996), “The art and practice of structure-based drug design: A molecular modeling perspective”, Medicinal Research Reviews, Vol. 16/1, pp. 3-50, https://doi.org/10.1002/(sici)1098-1128(199601)16:1%3C3::aid-med1%3E3.0.co;2-6.
- CASP14 (n.d.), 14th Community Wide Experiment on the Critical Assessment of Techniques for Protein Structure Prediction website, https://predictioncenter.org/casp14/ (accessed 12 January 2023).
- CBO (2021), Research and Development in the Pharmaceutical Industry, 8 April, Congressional Budget Office, Washington, DC, www.cbo.gov/publication/57025.
- DeSantis, C.E., J.L. Kramer and A. Jemal (2017), “The burden of rare cancers in the United States”, CA: A Cancer Journal for Clinicians, Vol. 67/4, pp. p. 261-272, https://doi.org/10.3322/caac.21400.
- EC (n.d.), “European Open Science Cloud”, webpage, https://research-and-innovation.ec.europa.eu/strategy/strategy-2020-2024/our-digital-future/open-science_en (accessed 12 January 2023).
- ELIXIR (n.d.), ELIXIR website, https://elixir-europe.org/ (accessed 12 January 2023).
- FDA (2021), Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) Action Plan, US Food and Drug Administration, Washington, DC, www.fda.gov/media/145022/download.
- Fontinelle, A. (2023). “Spinoff Definition, Plus Why and How a Company Creates One”. https://www.investopedia.com/terms/s/spinoff.asp.
- Goodsell, D.S. et al. (2021), “The AutoDock suite at 30”, Protein Science, Vol. 30/1, pp. 31-43, https://doi.org/10.1002/pro.3934.
- Gunning, D. and D.W. Aha, (2019), “DARPA’s explainable artificial intelligence (XAI) program”, AI Magazine, Vol. 40/2, pp. 44-58, https://doi.org/10.1609/aimag.v40i2.2850.
- Herper, M. (2017), “MD Anderson benches IBM Watson in setback for artificial intelligence in medicine”, 19 February, Forbes, www.forbes.com/sites/matthewherper/2017/02/19/md-anderson-benches-ibm-watson-in-setback-for-artificial-intelligence-in-medicine/.
- Hoffmann, T. and G. Marcus (2019), “The next level in chemical space navigation: Going far beyond enumerable compound libraries”, Drug Discovery Today, Vol. 24/5, pp. 1148-1156, https://doi.org/10.1016/j.drudis.2019.02.013.
- (2023). Lead Optimization. https://www.irbm.com/drug-discovery/lead-optimization
- Jayatunga, K.P. et al. (2022), “AI in small-molecule drug discovery: A coming wave?” Nature Reviews Drug Discovery, Vol 21/3, pp. 175-176, https://doi.org/10.1038/d41573-022-00025-1.
- Jumper, J. et al. (2021), “Highly accurate protein structure prediction with AlphaFold”, Nature 2, Vol. 596, pp. 583-589, https://doi.org/10.1038/s41586-021-03819-2.
- Kleinstreuer N.C. et al. (2014), “Phenotypic screening of the ToxCast chemical library to classify toxic and therapeutic mechanisms”, Nature Biotechnology, Vol. 32, pp. 583-591, https://doi.org/10.1038/nbt.2914.
- McGowan, E. (2022). “What Is a Startup Company, Anyway?”. https://www.startups.com/library/expert-advice/what-is-a-startup-company.
- Morgan, P. et al. (2018), “Impact of a five-dimensional framework on R&D productivity at AstraZeneca”, Nature Reviews Drug Discovery, Vol. 17, pp. 167-181, https://doi.org/10.1038/nrd.2017.244.
- NAIRR Task Force (2022), Envisioning a National Artificial Intelligence Research Resource (NAIRR): Preliminary Findings and Recommendations, National Artificial Intelligence Research Resource Task Force, Washington, DC, www.ai.gov/wp-content/uploads/2022/05/NAIRR-TF-Interim-Report-2022.pdf.
- OECD (2023), Artificial Intelligence in Science: Challenges, Opportunities and the Future of Research, OECD Publishing, Paris, https://doi.org/10.1787/a8d820bd-en.
- Szalay, K.Z. (2023). “AI in drug discovery”. https://www.oecd-ilibrary.org/sites/a8d820bd-en/1/3/3/8/index.html?itemId=/content/publication/a8d820bd-en&_csp_=be7a6e5e377bf806fc0a37f89d460d76&itemIGO=oecd&itemContentType=book#section-d1e9849-21e330d21d.
- Varadi, M. et al. (2022) “AlphaFold protein structure database: Massively expanding the structural coverage of protein-sequence space with high-accuracy models”, Nucleic Acids Research, Vol.7/50(D1), pp. D439-D444, https://doi.org/10.1093/nar/gkab1061.
- Wallach, I., M. Dzamba and A. Heifets (2015), “AtomNet: A deep convolutional neural network for bioactivity prediction in structure-based drug discovery”, arXiv, arXiv:1510.02855v, https://doi.org/10.48550/arXiv.1510.02855.
- Wikipedia (n.d.), “Flowchart”, webpage, https://en.wikipedia.org/wiki/Flowchart (accessed 10 September 2022).
- Wong, C.H. et al. (2019), “Estimation of clinical trial success rates and related parameters”, Biostatistics, Vol. 20/2, pp. p. 273-286, https://doi.org/10.1093/biostatistics/kxx069.















